Python-正则表达式
2018-11-15 19:55:582021-02-20 17:21:17
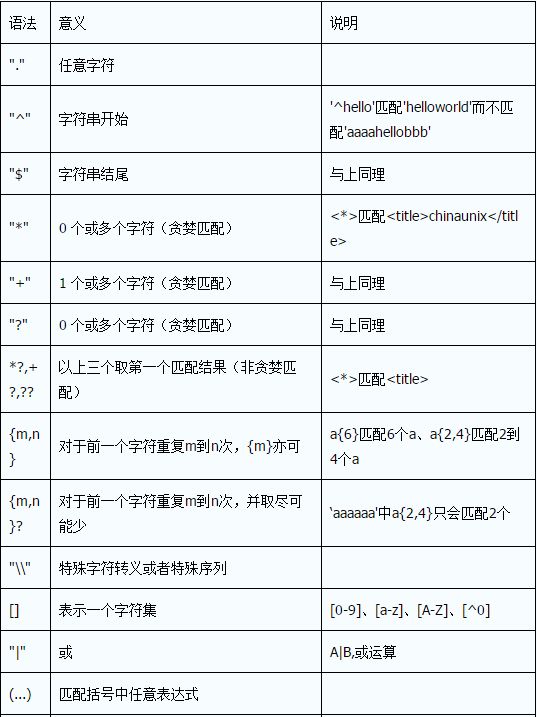
正则表达式
- 正则表达式匹配,就是按照一定的规则将特定的文本提取出来。
match
- match(0)法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 false。
match 示例
匹配目标
- 可以使用"()"将想提取的子字符串括起来,"()"实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式会依次对应每一个分组,调用 group()法传入分组的索引即可获取提取的结果。
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result0 = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
result1 = re.match('^Hello\s(\d+)\s(\d+)\sWorld', content)
print(result0)
print(result1)
print(result1.group(1), result1.group(2))
# 输出
<re.Match object; span=(0, 25), match='Hello 123 4567 World_This'>
<re.Match object; span=(0, 20), match='Hello 123 4567 World'>
123 4567
通用匹配
- ”.*“可以匹配任意长度字符串(换行符除外)。
- ”.“可以匹配任意字符(换行符除外)
- ”*“代表匹配前面的字符无限次
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello\s(\d+)\s(\d+)\s(.*?)Demo$', content)
print(result)
print(result.group(3))
# 输出
<re.Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'>
World_This is a Regex
贪婪匹配
使用”.*“通用匹配时,可能会得不到想要的结果:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$', content)
print(result.group(1))
# 输出
7
想要的结果是 123,却输出了 7。这就涉及到贪婪与非贪婪匹配了。
- 在贪婪匹配下, "._"会匹配尽可能多的字符。 所以在上面的正则表达式中,”._“直接匹配到了'Hello 123 456','\d'匹配到了'7'。
- 在非贪婪匹配下, "."会匹配尽可能少的字符。非贪婪匹配的写法是".?"。
import re
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result.group(1))
# 输出
123
在做匹配的时候,字符串中间尽量使用非贪婪匹配,但需要注意,如果匹配的结果在字符串结尾,".*?"就有可能匹配不到任何内容了。
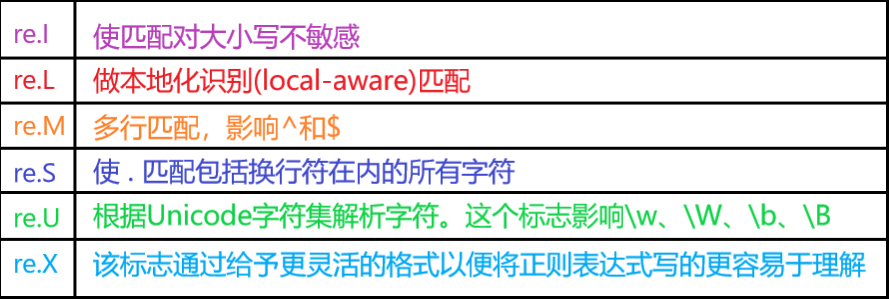
修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式 。
import re
content = '''Hello 123 4567 World_This
is a Regex Demo'''
result_none = re.match('^He.*?(\d+).*Demo$', content)
print(result_none)
result = re.match('^He.*?(\d+).*Demo$', content, re.S)
print(result)
# 输出
None
<re.Match object; span=(0, 52), match='Hello 123 4567 World_This \n is a Regex >
转义匹配
当遇到用于正则匹配模式的特殊字符时,在前面加反斜线转义一下即可 。
search
search (),它在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果 。
search 示例
import re
html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
</ul>
</div>'''
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
print(result.group(1), result.group(2))
result = re.search('<li.*?href="(.*?)"\ssinger="(.*?)">(.*?)</a>', html, re.S)
#print(result)
print(result.group(1), result.group(2), result.group(3))
# 输出
任贤齐 沧海一声笑
/2.mp3 任贤齐 沧海一声笑
findall
findall()方法会搜索整个字符串然后返回匹配正则表达式的所有内容。
findall 示例
...
...
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
print(result.group(1), result.group(2))
result = re.search('<li.*?href="(.*?)"\ssinger="(.*?)">(.*?)</a>', html, re.S)
# 输出
任贤齐 沧海一声笑
/2.mp3 任贤齐 沧海一声笑
/2.mp3 任贤齐 沧海一声笑
/3.mp3 齐秦 往事随风
/4.mp3 beyond 光辉岁月
/5.mp3 陈慧琳 记事本
sub
用来修改/替换文本
sub 使用示例
import re
import re
content = '54ak54yr50ir54ix5L2g'
content = re.sub('\d', '', content)
print(content)
# 输出
akyririxLg
compile
compile()可以将正则字符串编译成正则表达式对象,以便在以后的匹配中复用(也可以传入修饰符)。
import re
content0 = '2016-12-15 12:00'
content1 = '2016-12-17 12:55'
content2 = '2016-12-22 13:21'
pattern = re.compile('\d{2}:\d{2}')
result0 = re.sub(pattern, '', content1)
result1 = re.sub(pattern, '', content1)
result2 = re.sub(pattern, '', content2)
print(result0, result1, result2)
# 输出
2016-12-17 2016-12-17 2016-12-22